Hugo LuDatabricks $10bn Series J: Meta on the Cap Table spells the final endgameDatabricks is going after probably one of the most ambitious exits in the history of techJan 284Jan 284
InDev GeniusbySutanu DuttaWhy Kafka ditched ZookeeperFor many years, Apache Kafka relied on Apache ZooKeeper to manage metadata, cluster configurations and maintain a distributed state across…Nov 3, 2024Nov 3, 2024
InData Engineer ThingsbyDaniApache Iceberg: The Hadoop of the Modern Data Stack?The bigger they are the harder they fall.Dec 12, 20246Dec 12, 20246
InPinterest Engineering BlogbyPinterest EngineeringChange Data Capture at PinterestLiang Mou; Staff Software Engineer, Logging Platform | Elizabeth (Vi) Nguyen; Software Engineer I, Logging Platform |Nov 18, 20241Nov 18, 20241
Chunting WuIs there an Alternative to Debezium + Kafka?Evaluating open-source options to improve performance and scalability in CDC pipelinesNov 4, 20242Nov 4, 20242
InData Engineer ThingsbyYingjun WuKafka Has Reached a Turning PointIs Kafka still relevant in today’s evolving tech landscape? And where is Kafka headed in the future?Sep 23, 202414Sep 23, 202414
InLevel Up CodingbyDr. Ashish BamaniaGoogle’s New Algorithms Just Made Searching Vector Databases Faster Than EverA Deep Dive into how Google’s ScaNN and SOAR Search algorithms supercharge the performance of Vector DatabasesJun 18, 20244Jun 18, 20244
Kai WaehnerWhen NOT to Use Apache Kafka? (Lightboard Video)When NOT so use Apache Kafka: DOs and DONTs; no matter if you use open source, Confluent, Amazon MSK, Event Hubs, Redpanda, Warpstream, etcJun 21, 20242Jun 21, 20242
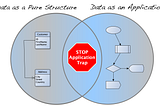
InTDS ArchivebyBernd WesselyDeliver Your Data as a Product, But Not as an ApplicationData as a product is an intriguing concept, but beware of the application trapJul 12, 20242Jul 12, 20242
InTDS ArchivebyBernd WesselyAvoid Building a Data Platform in 2024Why articles about ‘Building a Data Platform’ are mostly misleadingAug 13, 202412Aug 13, 202412
InTDS ArchivebyDario RadečićDuckDB and AWS — How to Aggregate 100 Million Rows in 1 MinuteProcess huge volumes of data with Python and DuckDB — An AWS S3 example.Apr 25, 20248Apr 25, 20248
InData Engineer ThingsbyLeo GodinNo, Data Engineers Don’t NEED dbt.But It Sure Does Solve a Lot of ProblemsJul 19, 202426Jul 19, 202426
InFAUN — Developer Community 🐾byAymen El AmriThe Hottest Open Source Projects Of 2023This article was originally posted on faun.dev.Dec 28, 202312Dec 28, 202312
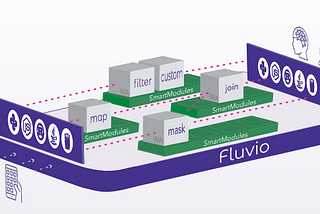
Florian TiebenFluvio: A Kafka + Flink Built Using Rust + WASMFluvio is a new open-source streaming platform that is built using Rust and WebAssembly (WASM). It is a combination of Apache Kafka and…Oct 5, 20233Oct 5, 20233
Kieran HealeyCached Takes: 80% of Companies do not need Snowflake or DatabricksThe cost for something that can be replicated free and open source is absurd. The Fortune 100 have a use case for these companies, the rest…Jul 14, 202321Jul 14, 202321
Rafael "Auyer" PassosHow I Decreased ETL Cost by Leveraging the Apache Arrow EcosystemIn the field of Data Engineering, the Apache Spark framework is one of the most known and powerful ways to extract and process data. It is…Feb 15, 20231Feb 15, 20231